
Python多线程同步、互斥锁、死锁
接着上篇多线程继续讲,上篇最后的多线程共享全局变量对变量的处理值出错在本文中给出解决方案。
出现这个情况的原因是在python解释器中GIL全局解释器锁。
GIL:全局解释器锁,每个线程在执行的过程都需要先获取GIL,保证同一时刻只有一个线程而已执行代码
线程释放GIL锁的情况:在IO操作等呃能会引起阻塞的system call之前,可以暂时释放GIL
但在执行完毕后,必须重新获取GIL, Python3中使用计时器(执行时间打到阀值后,当前线程释放GIL)
python使用多线程是并发 可以使用多线程利用多核的CPU资源
cpu密集型:也成为计算密集型,任务的特点是要进行大量的计算,消耗cpu资源,比如计算圆周率、对视频进行高清解码等等
全靠cpu的运算能力 这个时候单线程快
io密集型:涉及到网络、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成,因为 IO的速度远远低于CPU和内存的速度 这个时候多线程快。
那么如何解决多线程共享全局变量数据错误的问题呢,引入锁。
import threading a = 100 def func1(): global a for i in range(1000000): meta.acquire() # 上锁 a += 1 meta.release() # 释放锁 print(a) def func2(): global a for i in range(1000000): meta.acquire() a += 1 meta.release() print(a) # 创建锁 meta = threading.Lock() t1 = threading.Thread(target=func1) t2 = threading.Thread(target=func2) t1.start() t2.start() t1.join() t2.join() print(a)
至于锁的原理在下方粗略的画一张草图以供参考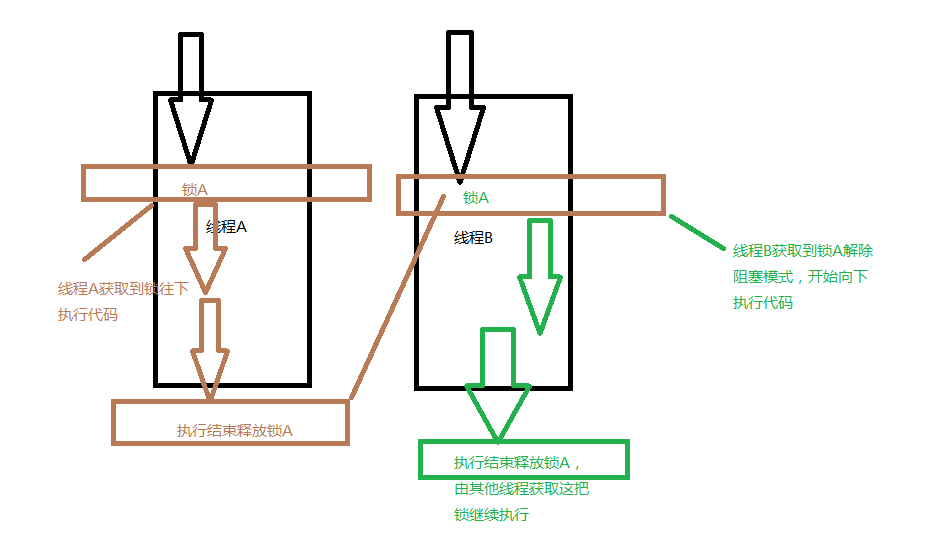

使用锁让每个线程有序的切换执行,不会出现数据混乱。
但是在使用锁的时候要注意不要写出死锁代码,附死锁代码参考,总结一句就是互相持有对方线程所需要的锁,造成死锁
import threading a = 100 def func1(): global a for i in range(1000000): meta_A.acquire() # 上锁 meta_B.acquire() # 上多把锁 产生了死锁 看下面代码 print('-------------1') a += 1 meta_B.release() meta_A.release() # 释放锁 print(a) def func2(): global a for i in range(1000000): meta_B.acquire() meta_A.acquire() print('------------2') a += 1 meta_A.release() meta_B.release() print(a) # 创建锁 meta_A = threading.Lock() meta_B = threading.Lock() t1 = threading.Thread(target=func1) t2 = threading.Thread(target=func2) t1.start() t2.start()
今天就写到这里,下一篇写一下队列
* 注:本文来自网络投稿,不代表本站立场,如若侵犯版权,请及时知会删除